
IDRC with the support of Kessler Foundation and Microsoft has launched ODD (Optimizing Diversity with Disability). The goal of ODD is to investigate bias in hiring algorithms using non-disability specific and synthesized disability specific employment data. In the next year, we will work with the community to create synthetic models of resume and job seeker data that will be tested with online hiring systems. Our objective is to better understand how to mitigate algorithmic bias and use this knowledge in future projects to develop algorithms that can optimize diversity.
About
In the work with did in our We Count project and Future of Work and Disability projectwe noticed that AI hiring tools were filtering out highly qualified candidates with disabilities. It is estimated that over 50% of companies will deploy some form of AI assisted or AI automated hiring tools in the next decade (Sage, Pego). We knew that AI hiring tools exploit data regarding past hiring to filter applicants by optimizing the characteristics of past successes. In optimizing past successes these tools are biased against diversification; while the companies deploying them have a commitment to diversity, equity, and inclusion. AI hiring tool options such as specifying “culture fit,” persona matching, team profiles, and favourite university, contribute toward creating a company monoculture. This is not good for company survival. It also filters out applicants with disabilities. Promising research has shown that algorithms that favour data exploration rather than data exploitation result in greater hiring diversity without compromising hiring success (Hiring as Exploration). This prior research focuses on race, origin, and gender diversity. ODD will extend this research to the more difficult area of disability. Unlike race, origin, and gender; disability has no common data characteristic other than distance from the average so that things made for the mainstream don’t work for you.
Why ODD?
We chose the name ODD because we are reclaiming a word that is often used pejoratively. People with disabilities are rejected because they are “odd,” but it is that oddness that prompts innovation and means that you can see the things that other people miss.
Our Team
Jutta Treviranus – Director
Vera Roberts – Project Manager
Cindy Li – Technical Manager
Antranig Basman – Sr. Inclusive Developer
David Pereyra – Project Coordinator
Caren Watkins – Inclusive Designer
Edward Thomas – Research Assistant
Project Architecture
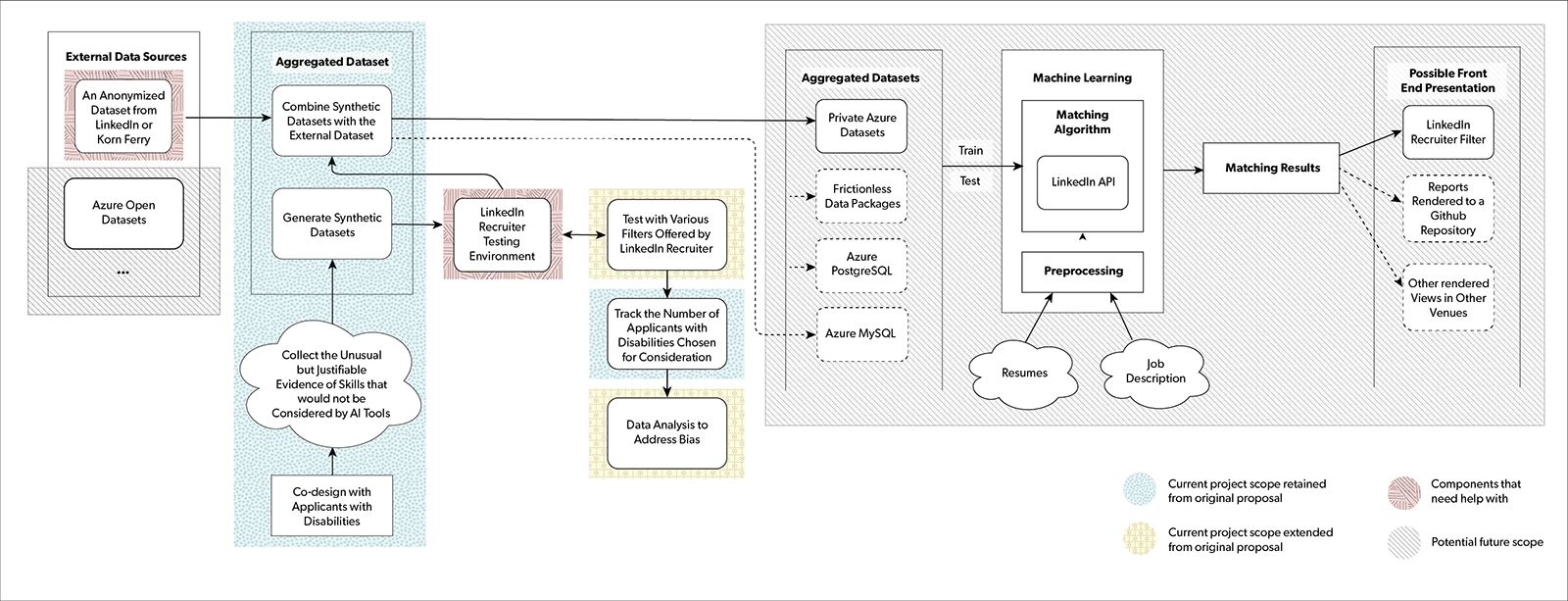
Project Architecture Description
There are four main phases:
- collect external data sources,
- synthesize data and create an aggregated data set,
- test the data set with various hiring filters and
- present the data set in multiple formats for new algorithm development, testing and front-end presentation.
The flow of the Current project scope is as follows:
- Data is collected from external sources such as LinkedIn or Korn Ferry. Help is needed from LinkedIn for their data set. A potential future data set is the Azure open data sets.
- Next, we will perform co-design with applicants with disabilities to collect the unusual but justifiable evidence of skill that would not be considered by an AI tool to create a synthetic dataset. We will combine the synthetic data with the external data to create an aggregated data set. This work was retained from the original project scope.
- Next, we will use the LinkedIn Recruiter testing environment to track the number applicants with disabilities chosen for consideration. This work is from the original project plan.
- We have extended the project scope to include testing with various filters offered by LinkedIn Recruiter and analyzing results to address bias. We will require assistance from LinkedIn for the test environment.
Potential future project scope includes:
- Publish the aggregated dataset as private Azure datasets as the first option. Other alternatives to make aggregated datasets available to other communities include Frictionless data packages such as using private Github repositories, Azure Postgres SQL or Azure MySQL databases
- Implement the matching algorithm using LinkedIn API
- Use the aggregated dataset to train and test the machine learning algorithm in the Machine Learning module
- When matching resumes with a job description, resumes and the job description will first be preprocessed, then passed along to the matching algorithm
- Display the matching results on the LinkedIn Recruiter filter interface. Other front end presentation alternatives include reports rendered to a Github repository or other rendered views in other venues

